1.选一个自己感兴趣的主题。
https://s.taobao.com/search?q=
2.网络上爬取相关的数据。
import requests
import re
def getHTMLText(url):
try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""def parsePage(ilt, html):
try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) tlt = re.findall(r'\"raw_title\"\:\".*?\"',html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price , title]) except: print("")def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号", "价格", "商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1]))def main():
goods = '手机' depth = 3 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44*i) html = getHTMLText(url) parsePage(infoList, html) except: continue printGoodsList(infoList)main()
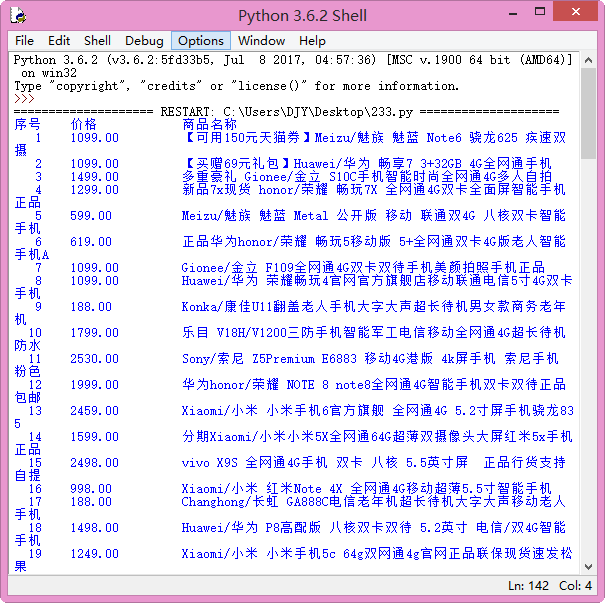
3.进行文本分析,生成词云。
import jieba
from wordcloud import WordCloudimport matplotlib.pyplot as plttxt=open('ye.txt','r',encoding='utf-8').read()mywc = WordCloud().generate(txt)plt.imshow(mywc)plt.axis("off")plt.show() 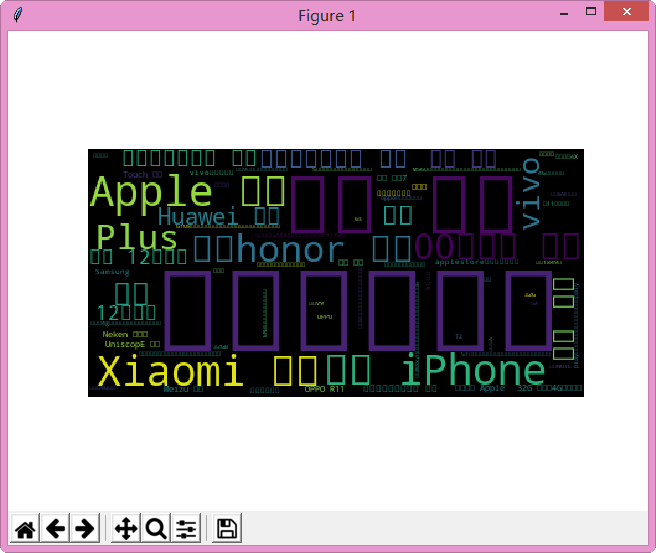
4.对文本分析结果解释说明。
从生成的云词看出iphone手机还是在搜索中占的量最多,也就是说销售的量也是最多,但是xiaomi,honor,vivo,huawei等国产手机的量还是不少的。可以说国产手机的产品力已经渐渐追上国际名牌手机。
5.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。